Introduction
Picture this: a production scheduler builds a tight, optimized schedule Monday morning. By Monday afternoon, a spindle goes down on the Mazak, a setup on the Haas ran 40 minutes long, and a batch of turned parts failed first-article inspection. The schedule is already fiction.
This gap — between the plan and the floor — exists because most scheduling systems run on planned data. Estimated cycle times. Assumed machine availability. Theoretical capacity. The moment real production begins, those assumptions start eroding.
Closing that gap means pairing scheduling algorithms with live shop floor data — feeding those algorithms continuously as conditions change. This guide covers which data types actually drive scheduling decisions, how algorithms range from simple dispatching rules to AI-driven dynamic sequencing, and what it takes to build the integration layer that connects the two.
Key Takeaways
- Shop floor scheduling sequences jobs, assigns resources, and manages task dependencies to maximize throughput and meet due dates.
- Scheduling algorithms are only as accurate as their input data — outdated inputs produce schedules that drift from reality within hours.
- Feed algorithms real-time machine status, actual cycle times, WIP progress, and scrap events to enable dynamic rescheduling against actual shop conditions.
- Algorithm options span simple dispatching rules (FIFO, EDD) through genetic algorithms and reinforcement learning — matched to your shop's complexity.
- Universal machine connectivity — including legacy CNCs — is the foundational step before any data-driven scheduling is possible.
What Shop Floor Scheduling Is and Why Data Integration Matters
Scheduling vs. Planning
Production planning answers what to make. Scheduling answers when and on which machine to make it.
Shop floor scheduling covers four core tasks:
- Determining job sequence and timing across machines and workstations
- Assigning labor and equipment resources to each operation
- Managing operation dependencies and routing order
- Committing to realistic delivery dates
A good schedule minimizes idle time, avoids resource conflicts, and keeps jobs moving through the routing in the correct sequence.
The challenge is that scheduling is a dynamic problem, not a static one. Machine failures, rush orders, and quality problems all require the schedule to be repaired after it's been issued. Academic rescheduling literature from NIST describes this precisely: disruptions are endemic to manufacturing, and schedules require continuous updating to remain executable.
Why Static Data Breaks Schedules
Scheduling algorithms are deterministic optimizers: their output is only as accurate as their input. Feed an algorithm estimated cycle times and assumed machine availability, and it produces an optimal schedule based on those estimates. The moment production starts and reality diverges from those estimates, the schedule quietly becomes invalid.
According to Deloitte, poor maintenance strategies alone can reduce productive asset capacity by 5% to 20%, and unplanned downtime costs industries an estimated $50 billion annually. Those losses compound when scheduling systems can't detect or respond to disruptions in real time.
Data integration solves this by replacing static assumptions with live machine conditions: current status, actual cycle times, WIP progress, and scrap events. The algorithm gets accurate inputs and can issue a revised schedule the moment those conditions shift.
Types of Shop Floor Data That Drive Scheduling Decisions
Not all machine data is scheduling-relevant. These five categories are the ones that actually change how a schedule should be built or revised.
Machine Status and Availability
Real-time signals indicating whether a machine is running, idle, in setup, or down are the foundation of capacity-aware scheduling. An algorithm cannot correctly assign a job to a machine it believes is available when that machine is actually offline.
Without live status data, the algorithm schedules against theoretical capacity rather than actual capacity — a distinction that compounds across every shift the moment a spindle alarm fires or a maintenance event runs long.
Actual vs. Planned Cycle Time
The delta between expected and actual cycle time is one of the most consistent sources of schedule drift. When jobs consistently run faster or slower than estimated, that variance compounds across dozens of operations and dozens of machines. A 2025 study published in Procedia CIRP analyzed machining cycle time anomalies using CNC and operational data, confirming that cycle time deviation is a measurable and consequential variable in CNC production environments.
Systems that capture actual cycle times per operation and feed that variance back into future estimates — rather than relying on static standards — produce progressively more accurate schedules over time.
WIP and Job Completion Status
Real-time job tracking tells the scheduling algorithm which operations are complete, which are in-process, and which are queued. The alternative is downstream sequencing based on the last manual update — which could be hours old. With live WIP data, the algorithm recomputes job sequences continuously as upstream operations complete, avoiding the situation where a bottleneck machine sits idle because no one updated the job status in the ERP.
Tooling, Setup, and Changeover Readiness
Setup time is consistently underestimated in static schedules, particularly in job shops running high-mix, low-volume work where changeovers are frequent and variable. Research examining setup and processing time variability in job shop environments found that setup-time variability should be specifically prioritized as a schedule-risk driver in functional layouts.
That's the exact environment where most CNC job shops operate. Actual setup duration data, captured over time, gives scheduling algorithms realistic changeover estimates — not optimistic ones built from stale standards.
Quality and Scrap Events
When a part fails inspection or a batch generates scrap, the job needs rework or a rerun. If the scheduling system doesn't know this has happened, all downstream operations for that job will be pushed past their due dates — silently. Rescheduling literature identifies three primary disruption categories that require schedule repair:
- Machine failures and unplanned downtime
- Rush orders and priority changes
- Quality failures, rework, and scrap
Integrating scrap events into the scheduling data model means downstream impacts get recalculated immediately — not discovered at the end of the shift.
Scheduling Algorithms: From Rules-Based to AI-Driven
Dispatching Rules: Fast and Simple
Priority dispatching rules are the most widely used scheduling logic in manufacturing ERP and MES systems. The four most common:
| Rule | Logic | Best For |
|---|---|---|
| FIFO | First In, First Out | Simple queues, equal-priority jobs |
| EDD | Earliest Due Date first | Minimizing lateness |
| SPT | Shortest Processing Time first | Minimizing average completion time |
| Critical Ratio | (Due date − today) ÷ remaining work | Balancing urgency and workload |

Dispatching rules are deterministic and computationally lightweight, making them practical for smaller job shops or straightforward routing environments. Their limitation is that each rule optimizes for a single objective and cannot balance competing constraints simultaneously. A 2025 paper on dynamic dispatching rule selection in Computers & Industrial Engineering identifies these four as the standard baseline taxonomy in scheduling research.
Heuristic and Metaheuristic Algorithms
For mid-complexity problems, heuristic approaches find good-enough solutions quickly without guaranteeing mathematical optimality. The NEH algorithm, for example, is a well-established heuristic for minimizing makespan in flow shop environments.
Metaheuristics search the solution space more aggressively, using structured randomness to escape local optima:
- Simulated annealing — accepts worse solutions probabilistically to avoid getting trapped, applied to job shop makespan minimization
- Tabu search — maintains a memory structure to avoid revisiting recent solutions, effective for medium-complexity job shops
These methods perform well where exact optimization would be computationally impractical, without requiring the data volume that AI-driven approaches demand.
Genetic Algorithms for Job Shop Scheduling
Genetic algorithms (GAs) apply evolutionary logic to scheduling: a population of candidate schedules is encoded as "chromosomes" and evolved through selection, crossover, and mutation operators across many generations until a near-optimal schedule emerges.
GAs are particularly well-suited to complex job shop problems with multiple machines, varied routings, and competing constraints — exactly the environment where dispatching rules break down. A case study published in Computers in Industry reported approximately 30% makespan improvement over the existing scheduling system using a GA-based approach — a meaningful result, though not a universal benchmark.
One critical requirement: GAs need real-world inputs — actual processing times, current machine availability — to produce schedules that hold up on the floor.
AI and Machine Learning-Based Dynamic Scheduling
Reinforcement learning (RL) represents the current research frontier. Rather than solving a static scheduling problem and re-solving it periodically, RL-based schedulers learn from historical and real-time data to make sequencing decisions as conditions shift.
A 2024 paper in Applied Soft Computing proposes a PPO-based deep reinforcement learning model for dynamic job shop scheduling, demonstrating that RL-based approaches can adapt to disruptions without requiring full re-optimization from scratch.
Unlike classical algorithms, ML-based schedulers improve over time as they accumulate shop floor data. That makes the quality of the data integration layer directly consequential — better data in, better scheduling decisions out.
Choosing the Right Algorithm
| Algorithm Type | Best Use Case | Data Requirements | Complexity |
|---|---|---|---|
| Dispatching rules | Simple flow shops, single-machine queues | Minimal | Low |
| Heuristics (NEH) | Flow shop, 5–15 machines | Moderate | Low-Medium |
| Metaheuristics (SA, tabu) | Mid-complexity job shops, 10–50 machines | Moderate | Medium |
| Genetic algorithms | High-mix, complex routing, varied constraints | High (actual times needed) | High |
| RL/ML-based | High-volume, data-rich, dynamic environments | Very high (historical + real-time) | Very High |

How Real-Time Data Integration Closes the Scheduling Loop
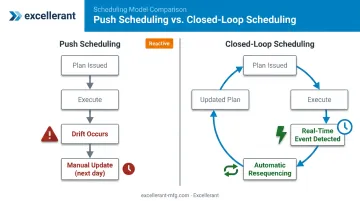
Push vs. Closed-Loop Scheduling
Most shops today operate on push scheduling: a plan is issued, executed until the next planning cycle, and updated manually when someone notices a problem. The schedule and the floor drift apart continuously between updates.
Closed-loop scheduling inverts this: the schedule is continuously updated as actual data flows back from machines and operators. Consider a 20-minute unplanned breakdown detected in real time. That event triggers automatic resequencing of queued jobs across available machines — a response impossible without live data. With manual push scheduling, the same breakdown might not appear in the schedule until the next morning's planning meeting.
McKinsey's discrete manufacturing Industry 4.0 research documented an industrial equipment manufacturer that reduced subassembly WIP time from 3 days to 4 hours through real-time production visibility — illustrating what closed-loop data flow does to throughput, not just scheduling accuracy.
Communication Protocols and Data Standards
Integrating machines from multiple vendors into a single scheduling data stream requires a common data language. Three standards define this space:
- MTConnect — an open, royalty-free standard that defines semantic data tags and agent behavior for manufacturing equipment, allowing machines to provide data using common definitions rather than proprietary formats. Excellerant is an MTConnect Standards Committee Voting Member, giving the company direct involvement in how the standard evolves.
- OPC-UA — the OPC Foundation's platform-independent architecture for broader industrial equipment interoperability, complementing MTConnect for non-CNC devices and PLCs.
- Vendor-specific protocols — Fanuc FOCAS, HAAS MNET, Mazak Mazatrol, and Heidenhain TNCremo provide direct data access for those specific control families.
Without these standards, every machine from every vendor requires a custom integration — expensive, fragile, and difficult to maintain as the floor changes.
Data Contextualization: From Raw Signals to Scheduling Inputs
Raw machine signals need to be translated into scheduling-relevant states before they're usable. Spindle load percentages, alarm codes, and program numbers mean nothing to a scheduling algorithm until they map to states it can act on: running, idle, in-setup, or down.
That translation layer is what separates raw sensor data from actionable scheduling inputs. Excellerant's platform handles this by conforming diverse data streams into a unified computing environment, with a predictive rule engine that incorporates machine data into its analytics suite. A scheduling algorithm then receives a consistent machine state model regardless of whether the source is a modern Fanuc CNC on ethernet or a 30-year-old knee mill on RS-232.
Modern Machine Shop's 2026 Top Shops data documented a 46% increase in five-axis utilization at Coastal Machine and Supply after implementing machine monitoring — showing how contextualized machine data translates directly into recovered capacity on the floor.
Implementing Shop Floor Data Integration: Practical Steps
Step 1: Establish Machine Connectivity
The first and most technically challenging step is connecting every machine on the floor to a data collection layer. Most job shops run a mix of machine vintages — modern CNCs with ethernet ports alongside 20- and 30-year-old machines that predate networking entirely.
A universal connectivity solution must handle:
- Modern CNCs via ethernet or WiFi (plug-and-play)
- Legacy RS-232 machines via serial communications or wireless DNC adaptors
- Older paper-tape and BTR machines via specialized serial hardware
- PLC-controlled equipment via intermediary PLC devices
Excellerant's machine monitoring platform is built specifically to handle this connectivity gap, connecting any mix of new and legacy CNC machines through a single unified platform, supporting Fanuc FOCAS, HAAS MNET, Mazak Mazatrol, MTConnect, OPC-UA, and Heidenhain TNCremo alongside RS-232 and serial legacy connections. Shops running 40-year-old equipment don't need to replace machines to extract scheduling-relevant data.
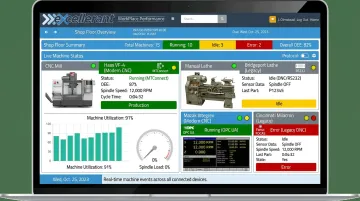
Step 2: Normalize and Contextualize Data
Raw data from disparate machines must be mapped to a common data model before it can feed scheduling algorithms. Key normalization tasks:
- Translate alarm codes into standard downtime reason categories (tooling, machine fault, operator, material)
- Map program identifiers to job and operation references in the ERP
- Capture accurate timestamps to support sequencing analysis across machines
- Categorize machine states into scheduling-relevant statuses (running, idle, in-setup, down)
Skipping this step is a common implementation failure. Data flows, but the scheduling algorithm receives inconsistent or uninterpretable inputs and produces flawed sequences as a result.
Step 3: Integrate with Your Scheduling and ERP/MES Layer
The integration architecture follows this sequence: machine data layer → monitoring/MES platform → live shop floor state model → scheduling algorithm inputs.
Two integration models exist:
- Event-driven integration — the scheduler triggers when a significant event occurs (machine goes down, job completes, scrap is reported). Response to disruptions is faster, making this the better fit for high-mix, dynamic environments.
- Time-interval polling — the scheduler receives updated data every N minutes. Simpler to implement. Acceptable for lower-complexity environments where near-real-time is sufficient.
Excellerant's platform supports bi-directional ERP integration with SAP, Oracle, Epicor, JobBoss, and Global Shop Solutions via Open API, pushing real-time machine and operator data into the ERP while pulling job and work order data back to the floor. The Finite Dynamic Scheduler closes the loop with live machine status and OEE feedback, rescheduling dynamically against actual conditions rather than static assumptions.
Frequently Asked Questions
What is shop floor scheduling?
Shop floor scheduling sequences and times production jobs across machines and workstations, assigning resources and managing operation dependencies to maximize throughput and meet delivery commitments. It answers when and on which machine each job runs — distinct from production planning, which determines what to make.
Which algorithm is best suited for solving complex job shop scheduling problems?
Genetic algorithms and metaheuristics like simulated annealing and tabu search are best suited for complex job shop environments with varied routing and competing constraints. They explore large solution spaces and balance multiple objectives simultaneously — territory where exact optimization methods become computationally impractical.
What is job shop scheduling using a genetic algorithm?
This approach applies evolutionary computation — encoding candidate schedules as chromosomes, then evolving a population through selection, crossover, and mutation — to find near-optimal job sequences across machines with complex, varied routings. It's particularly effective where no single dispatching rule can produce a good global solution.
What data does a scheduling algorithm need from the shop floor?
The core inputs are machine availability and status, actual versus estimated cycle times, WIP and job completion status, tooling and setup readiness, and quality or scrap events. Together, these allow the algorithm to schedule against real capacity rather than theoretical capacity.
How does real-time machine data improve production scheduling?
Real-time data enables closed-loop scheduling, where the algorithm continuously updates job sequences in response to actual conditions — downtime, cycle time variance, scrap events — rather than following a static plan that drifts further from reality as the shift progresses.
Can legacy CNC machines be integrated into a modern scheduling data system?
Yes — legacy machines connect through monitoring solutions that support older protocols like RS-232, serial DNC, and vendor-specific interfaces. A universal connectivity layer that handles any machine brand or vintage is the key enabler for shops that need scheduling-relevant data from every machine without replacing older equipment.